大家在使用软件时基本上都遇到过乱码的问题,这是因为字符的编码和解码方式不一致导致的。由于计算机只认二进制数据,因此程序在存储、处理、传输字符时,需要将字符转化成二进制数据。通俗来讲,编码就是将字符转化为二进制数据,解码就是将二进制数据转化为字符。
问题描述
渠道反馈,我们上送的支付信息里存在乱码,影响渠道风控结果,会导致支付失败。
乱码信息
原始信息Pendientes largos con diseño de diamante de imitación con cuenta hoja
字符集
字符集是指多个字符的集合。不同的字符集包含的字符不一样、字符数量不一样、对字符的编码也不一样。
GB2312 是中国国家标准的简体中文字符集,GB2312 收录简化汉字(6763 个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。而 ASCII 字符集只包含了 128 字符,这个字符集收录的主要是英文字母、阿拉伯数字和一些简单的控制字符。
编码
- 「编码」在汉语里可以作动词使用。
- 作动词使用时,编码就是把一个字符转换成一个字节序列,以便在网络中传输或者存储到本地。
- 「编码」还可以做名词使用。
- 作名词使用时,就是指一种具体的编码格式。比如 ASCII 编码,GBK 编码,UTF-8 编码。
Unicode 和 UTF-8 的区别
Unicode 是一个囊括了世界上所有字符的字符集,其中每一个字符都对应唯一的编码值(code point)。 Unicode 字符要存储要传输怎么办,它不管,具体怎么编码,你们可以自己去实现,可以用 UTF-8、UTF-16 等。
Mac 可以用 xxd 命令查看字符编码:

- 字符
A的 Unicode 编码值 是U+0041,UTF-8 编码是41,0a是换行符。 - 字符
好的 Unicode 编码值是U+597D,UTF-8 编码是e5a5bd。
原因定位
数据传输发生乱码通常与字符编码有关。这里用的应该不是 UTF-8 编码,所以产生了乱码。
业务代码
注入 restTemplate
restTemplate 配置
请求渠道
RestTemplate 源码分析
从 RestTemplate.postForEntity 方法一路跟进来,发现涉及字符编码的是 HttpMessageConverter。
ResponseEntityResponseExtractor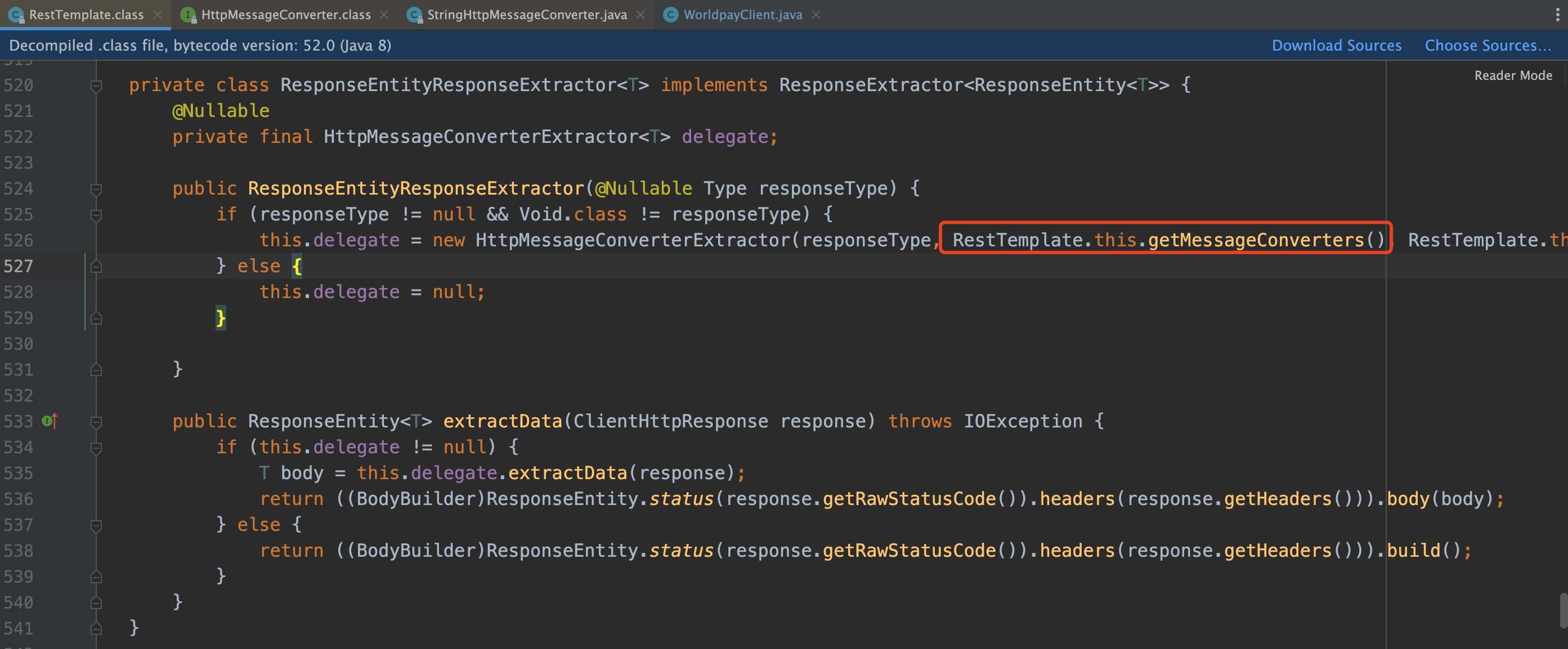
HttpMessageConverter 存在多个实现类,我们这里用到的是 StringHttpMessageConverter,它的 默认字符集是 ISO_8859_1。
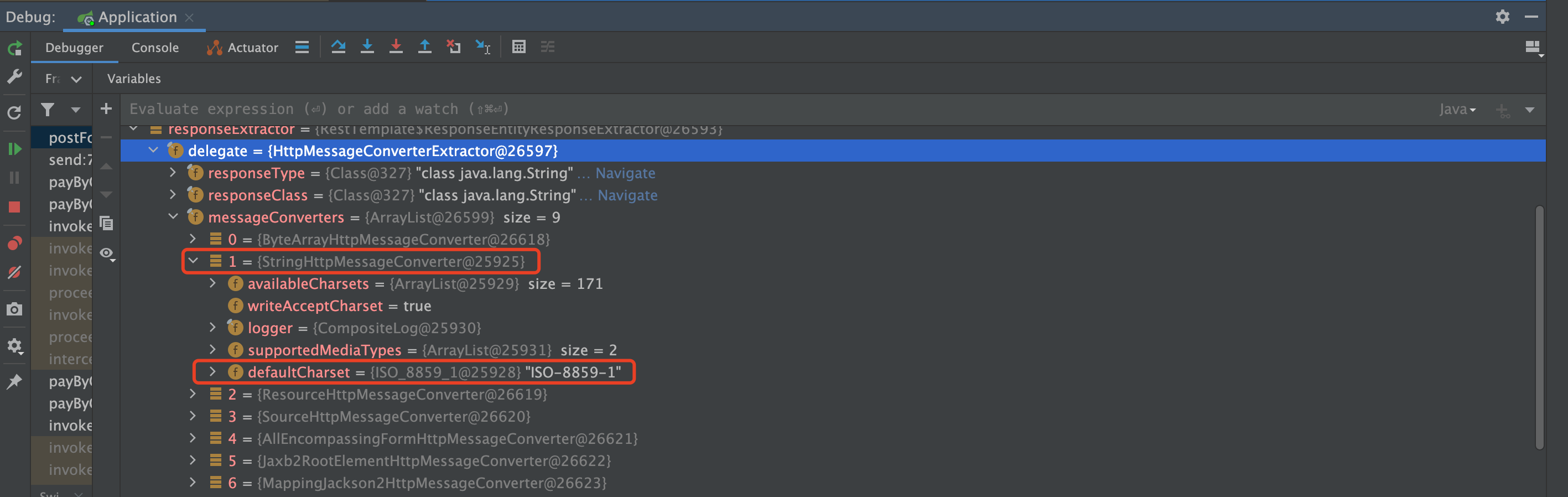
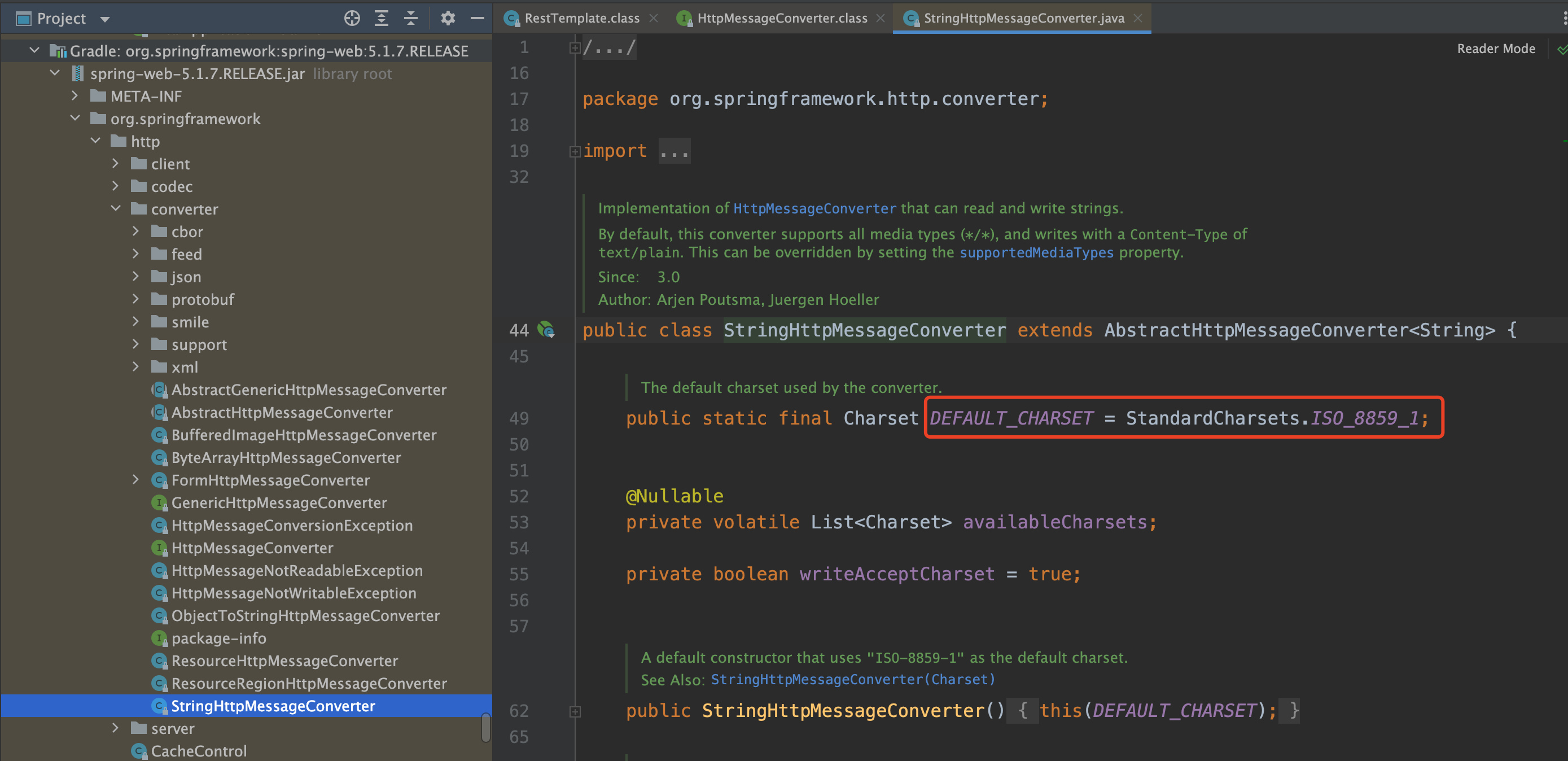
StringHttpMessageConverter 中用到的 关键方法是 getContentTypeCharset。
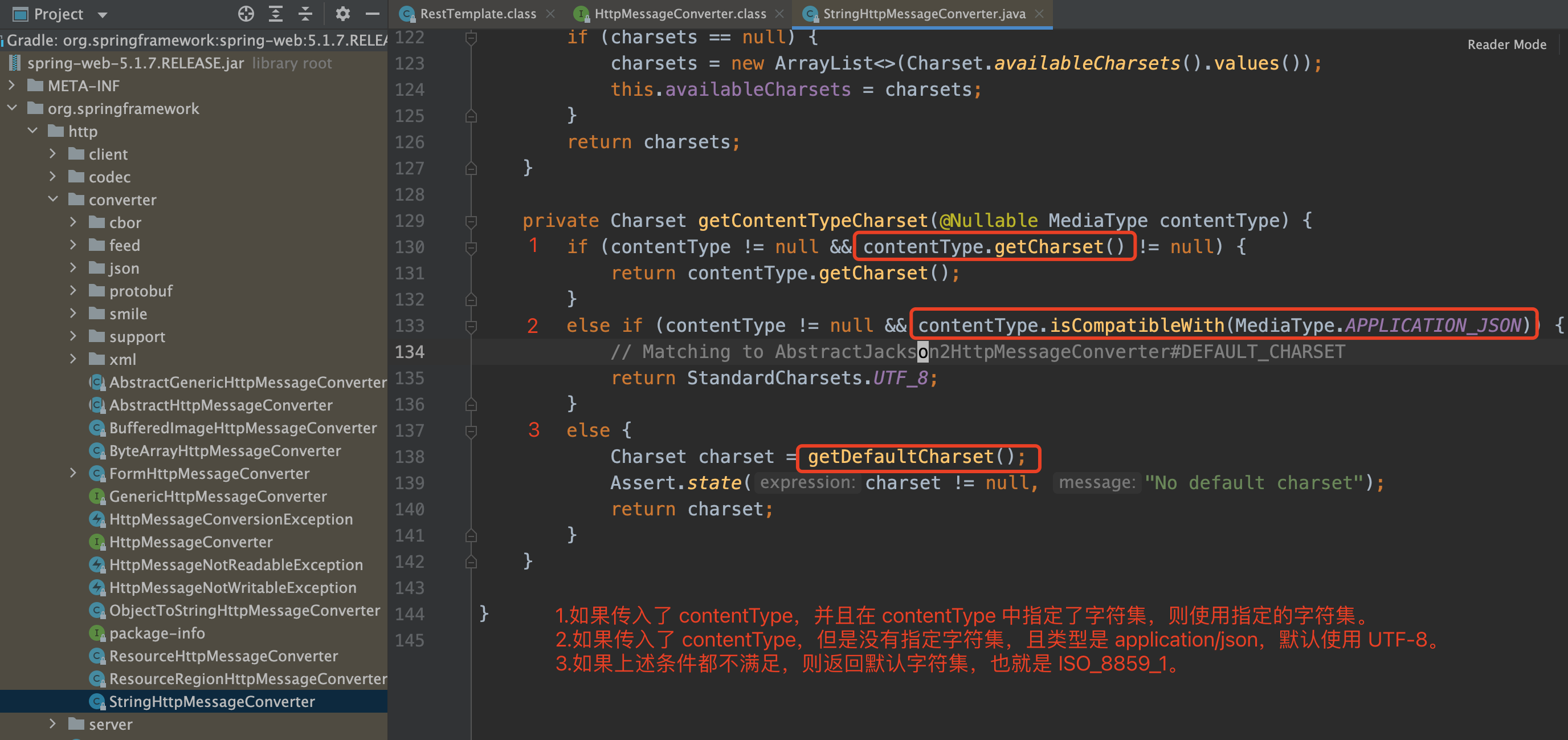
原因分析
- 首先业务代码在 RestTemplate 配置中没有指定 StringHttpMessageConverter 的字符集,所以它用的是默认字符集 ISO_8859_1。
- 又因为上送的 contentType 是
text/xml,不是application/json,StringHttpMessageConverter 无法使用 UTF-8 进行编码,只能使用默认的编码(ISO_8859_1)。 - 最终导致请求渠道时使用的编码方式是 ISO_8859_1,而不是 UTF-8,产生乱码。
修复方案
知道原因之后修复起来就很快,这里提供两个修复方案:
方案一
上送 contentType 时指定字符集为 UTF-8,即 text/xml;charset=UTF-8。
- 优点是改动范围小,影响面小。
- 缺点是可能其他人还会再踩同样的坑。

优先返回 contentType 中指定的字符集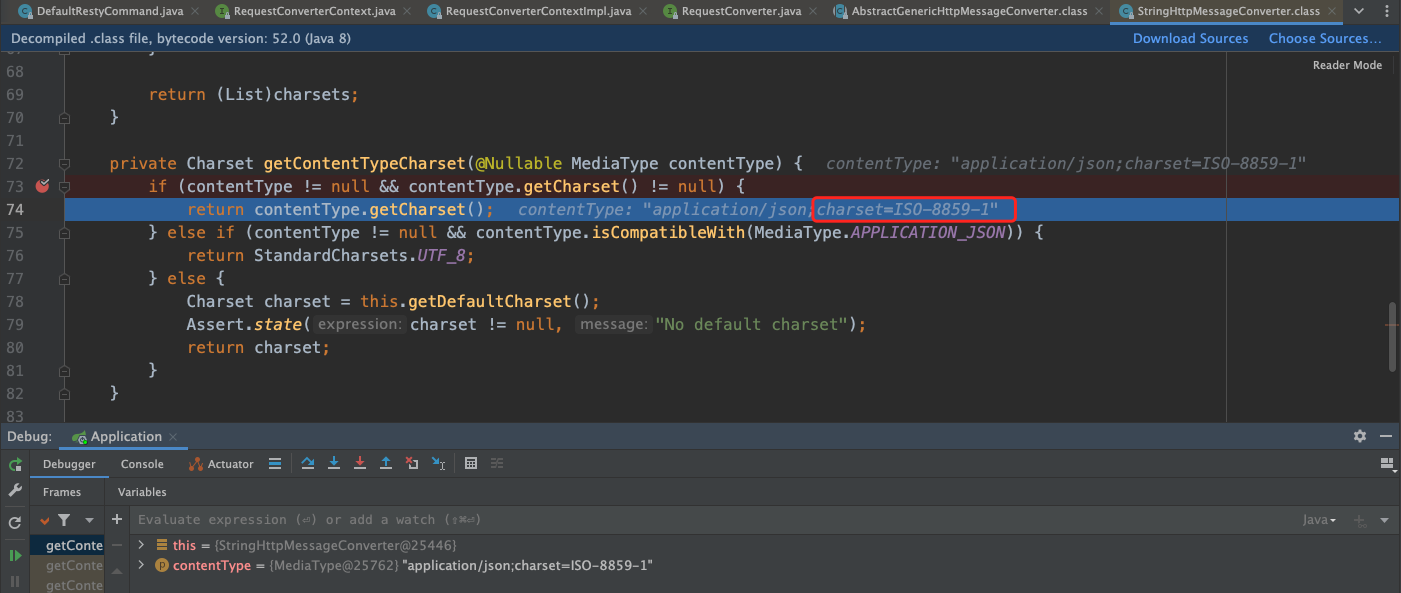
方案二
修改 RestTemplate 中 StringHttpMessageConverter 的默认字符集为 UTF-8。
- 优点是从根本上解决乱码问题,避免其他人踩同样的坑。
- 缺点是影响面广,需要进行充分的测试。
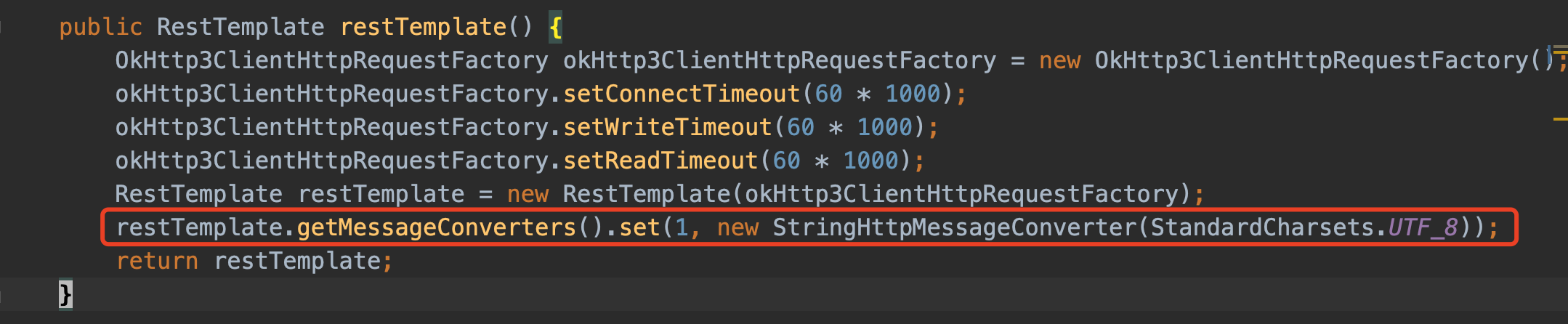
StringHttpMessageConverter 中默认的字符集变成了 UTF-8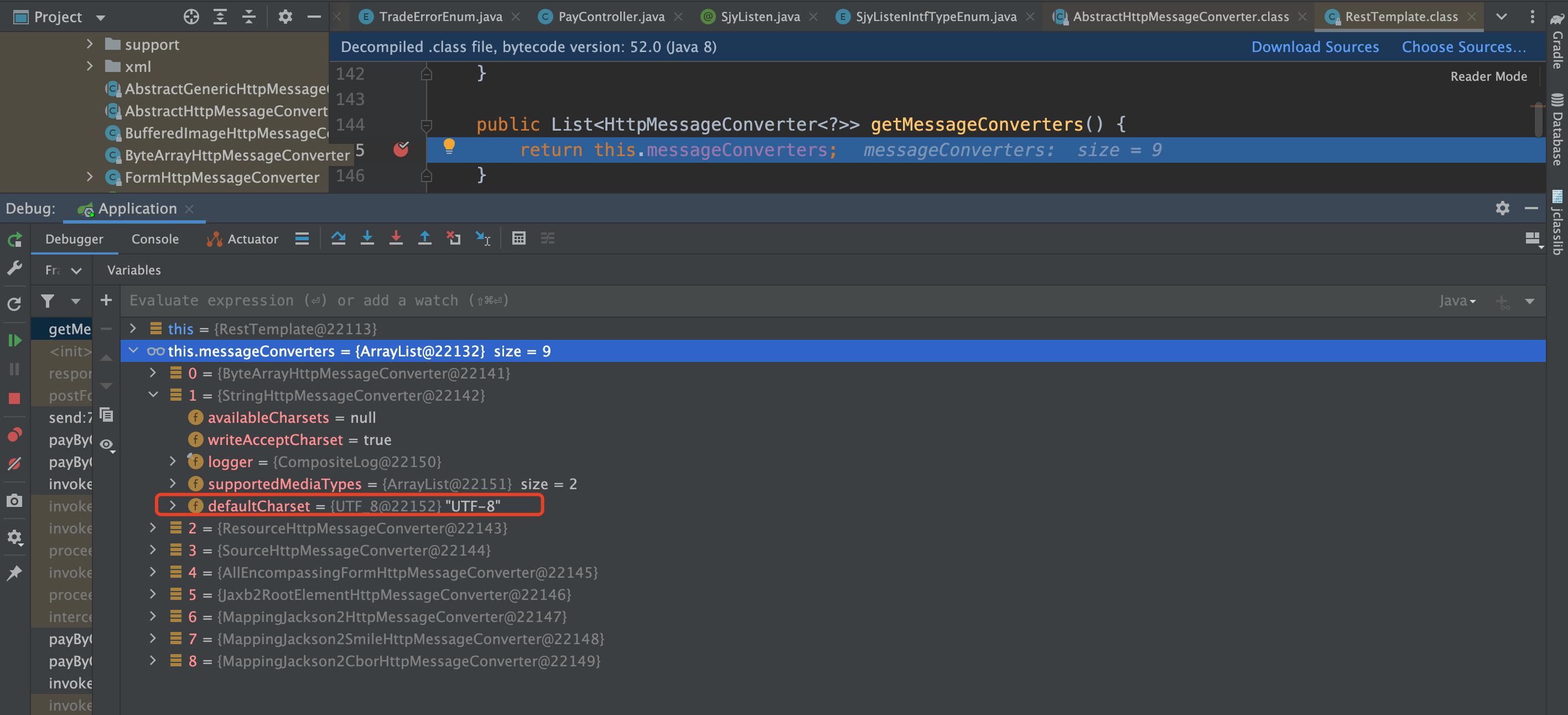
最终选择了方案二,充分回归后上线,彻底修复了乱码问题。
小结
- StringHttpMessageConverter 的 默认字符集是 ISO_8859_1(西欧语言),而不是 UTF-8(这可能和 作者 是荷兰人有关吧),个人认为其实是比较坑的,希望 Spring 后续版本能改进一下。